

NovaSeq X 시리즈 주문
발전된 화학 반응, 광학 및 인포매틱스가 결합되어 뛰어난 속도와 데이터 품질, 뛰어난 처리량과 확장성을 제공합니다.
연구자들이 자신의 데이터를 생물학적 맥락에 적용하는 데 도움이 되도록 고도로 큐레이션된 공공 데이터를 사용하여 개인용 omics 데이터를 분석하는 대화형 omics 지식 베이스.
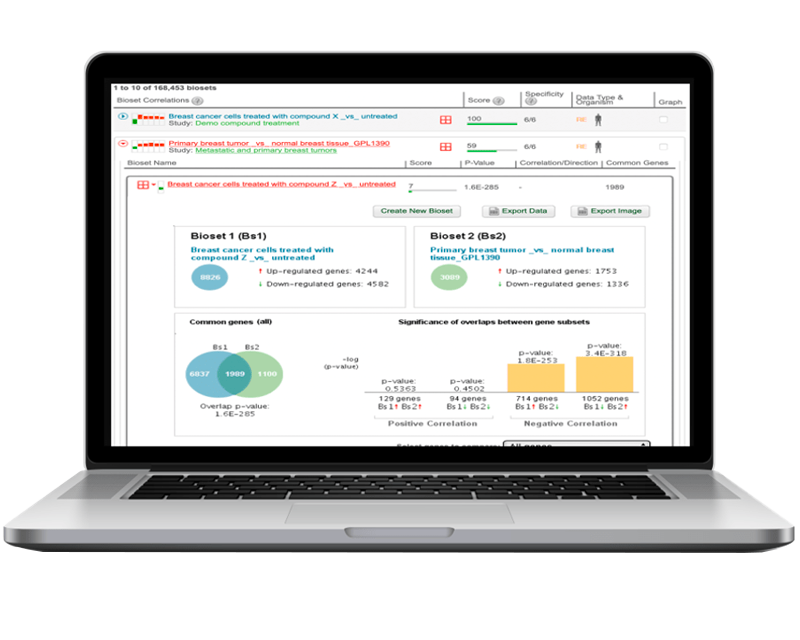
Correlation Engine은 세계 최대의 생물학적 데이터베이스 중 하나로 생명과학 연구자들에게 방대한 고품질 전장 유전체 분석과 통찰력 있는 과학적 도구에 대한 전례 없는 접근성을 제공합니다. 지식 기반은 전장 유전체 연구의 표준화된 분석에서 도출된 수십억 개의 데이터 포인트를 조사하여 새로운 발견을 가능하게 합니다.
Correlation Engine은 다음을 제공합니다.

Correlation Engine의 256K 엄선된 오믹스 유전자 시그니처를 이용하여 귀하의 데이터에 대해 신속히 상관 관계를 확인하고 질문해 보세요.
| Instruments | MiSeq System, NextSeq 550 System, NextSeq 2000 System, NextSeq 1000 System, MiSeqDx in Research Mode, MiniSeq System, NextSeq 550Dx in Research Mode, NovaSeq X System, NextSeq 500 System, iScan System, NovaSeq 6000 System, NovaSeq X Plus System |
|---|---|
| Software format | Cloud, Cloud |
| Technology | Microarray, Sequencing |
![]()
ISO 27001 Certified by Schellman
Illumina has received ISO 27001 certification of its information security management system (ISMS) supporting Correlation Engine. This certification ensures that sensitive data contained or collected by these solutions are protected. The certification was performed by Schellman, an ANSI National Accreditation Board (ANAB) and United Kingdom Accreditation Service (UKAS) accredited certification body based in the US.
![]()
ISO 27701 Certified by Schellman
Correlation Engine is compliant with global and local data privacy and requirements with 27701:2019 certification.
![]()
GDPR
Correlation Engine features multiple system controls that you can use to manage authorization, authentication, and data control, including deletion as needed. Access logs are retained for seven years. These features help researchers ensure compliance with the General Data Protection Regulation.
Correlation Engine은 고도로 큐레이션된 공공 데이터와 함께 개인 데이터를 생물학적 맥락에 배치하는 사용하기 쉬운 대화형 유전체학 분석 플랫폼을 제공합니다. 애플리케이션은 질병 기전, 약물 표적, 예후 또는 예측 생체표지자를 식별하기 위한 초기 단계 연구를 지원합니다.
안전한 고성능 시퀀싱 운영을 위한 사용이 간편한 클라우드 기반 유전체 실행 관리 및 생물정보학 컴퓨팅 및 스토리지 환경.
직관적인 기기 내장 런 설정 및 모니터링.
차세대 염기서열분석(NGS) 데이터의 정확하고 포괄적이며 효율적인 이차 분석.
BaseSpace Sequence Hub offers NGS data analysis apps for common Illumina sequencing methods.
원활한 시퀀서 통합과 유연한 워크플로우를 위한 안전하고 확장 가능한 생물정보학 플랫폼.
Correlation Engine
고도로 엄선된 공개 데이터로 생물학적인 맥락에 사적 오믹스 데이터를 포함시키는 상호적 오믹스 지식베이스입니다.
설명 가능한 AI 및 사용자 구성 자동화를 지원하여 희귀 질환 유전체학 및 기타 생식세포 연구 애플리케이션을 위한 고효율 데이터 해석 워크플로우를 지원합니다.
주요 생체표지자를 식별하고 유전자 시그니처의 어떤 유전자가 주요 질병 영역, 최적의 치료적 표적, 작용 기전에 대한 최선의 표지자를 제공하는지를 발견합니다.
약물의 새로운 목적을 나타내는 유전자-질병 화합물 링크를 발견하기 위해 역상관관계를 찾습니다.
캠퍼스 전체에서 연구원들이 고도로 큐레이션된 공공 유전체 데이터를 쿼리하고 사용하여 데이터를 맥락화하여 연구 프로젝트를 가속화하고 출판물을 생성할 수 있습니다.
공개 독성학 연구를 활용하여 화합물 시그니처를 평가하고, 큐레이션된 연구 또는 메타 분석 앱을 사용하여 알려진 다른 독성유전체 시그니처와의 중복을 발견합니다.
Illumina provides an innovative portfolio of NGS systems, products, and services for many phases of the drug development pipeline.
멀티오믹스 프로파일링을 사용하여 발견 역량을 크게 강화하고 유전형을 표현형에 더 잘 연결합니다.
Accelerate coronavirus detection and identification, perform host response studies, simplify your sample tracking, and contribute to public databases, free of charge.

데이터 유형 전반에 걸친 상관관계
주어진 쿼리에 대해 새로운 상관 관계 및 연관성을 신속하게 식별하여 유전자, 질병, 화합물, 조직 및 경로 간의 데이터 중심 연결을 드러냅니다.

신체 아틀라스
Body Atlas는 유전자가 발현되는 위치와 그 위치 내의 발현 수준에 대한 통찰력을 제공합니다.

질병 아틀라스
질병 아틀라스는 질병, 특성 및 쿼리된 데이터와 관련된 상태 간의 상관관계를 제공합니다.

약리학 아틀라스
Pharmaco Atlas는 화합물 발견, 화합물에 대한 유전체 및 후성유전체 반응, 질의 데이터와 관련된 치료를 지원합니다.
당사의 변형 주석 및 분석 소프트웨어 도구는 연구자들이 대량의 유전체 데이터에서 생물학적 통찰력을 추출하고 보고하는 데 도움이 될 수 있습니다.
Correlation Engine을 활용하는 정교한 다중오믹 분석 워크플로우를 살펴보십시오.
아니요. 현재 Correlation Engine은 인간 생물학 및 동물 모델 시스템만 지원합니다. 그러나 이 플랫폼은 감염에 대한 숙주 반응을 분석하는 데 사용할 수 있습니다.
상관 엔진은 RNA 발현(RNA-Seq), 유전형/SNP GWAS, DNA 단백질 상호작용 분석, 체세포 돌연변이 분석 및 DNA 메틸화 분석을 지원합니다.
Correlation Engine은 상호 작용이 가능하고 사용하기 쉬운 인터페이스와 사전 구축된 워크플로우를 포괄적인 고품질 큐레이팅된 공개 데이터와 결합하여 빠른 결과를 제공하므로 사용자는 지체 없이 다음 실험으로 진행할 수 있습니다.
상관 엔진에는 23,000건 이상의 연구가 있습니다. 상관 엔진에 대한 연구는 매주 업데이트됩니다.
Correlation Engine은 대부분의 Affymetrix, Illumina, Agilent 및 GE Healthcare 플랫폼에서 NCBI 유전자 ID, 유전자 기호, NCBI 등록 번호, ENSEMBL ID, RefSeq 식별자, IPI ID 및 사용자 지정 ID를 포함한 대부분의 공개 및 표준 상용 플랫폼 식별자를 인식합니다.
Correlation Engine은 독점적 순위 기반 통계를 사용하여 가져오는 데이터와 다른 모든 실험 데이터 간의 연관성을 계산합니다. 이를 통해 세계 실험의 맥락 내에 실험 결과를 배치하여 결과를 검증하고, 새로운 연관성을 발견하고, 새로운 실험을 설계할 수 있습니다. 이는 귀하의 데이터를 모든 생물군과 연관시켜, 귀하의 연구를 구성하는 유전자 또는 단백질 간의 공통적인 특징을 발견할 수 있게 합니다.
Correlation Engine은 PubMed의 1,900만 개 이상의 초록과 PubMed Central의 130,000개 이상의 전문 간행물을 색인화합니다. 문헌 검색의 경우, Correlation Engine은 다음과 같은 여러 가지 휴리스틱을 사용합니다.
.edu 이메일 계정을 가진 학술 연구원은 여기에서 등록하여 30일 무료 체험을 시작할 수 있습니다. 또는 무료 6개월 체험판에 관심이 있는 COVID-19 연구자 또는 구매에 관심이 있는 상업 고객의 경우 아래 가입 옵션을 사용하십시오.
귀하의 이메일 주소는 결코 제3자와 공유되지 않습니다.
발전된 화학 반응, 광학 및 인포매틱스가 결합되어 뛰어난 속도와 데이터 품질, 뛰어난 처리량과 확장성을 제공합니다.
클러스터 밀도와 판독 길이를 높여 이전 버전에 비해 시퀀싱 품질 점수를 개선하는 최적화된 시약 키트입니다.

FFPE 조직의 모든 주요 변이 계열과 유전자 시그니처(TMB, MSI, HRD)를 포함하는 대형 범암 패널로 CGP를 활성화합니다.
광범위한 시퀀싱 애플리케이션에 사용하기 위한 매우 정확한 데이터를 생성하는 효율적이고 빠른 통합 라이브러리 프렙 워크플로우입니다.
Illumina Connected Analytics를 통해 정보학을 운용하고 과학적 통찰력을 얻으십시오. 가격, 구독 등에 대한 정보는 당사에 문의하십시오.

DRAGEN 2차 분석을 통해 유전체학 통찰력을 극대화하고, 최신 업데이트에 대해 알아보고, FAQ를 읽고, 제품 지원을 확인해 보세요.
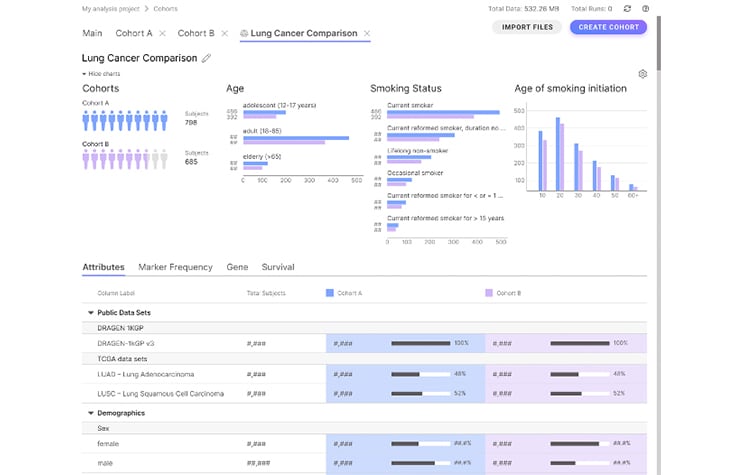
코호트를 신속하게 구축하고 탐색하기 위해 개인 데이터와 공개 데이터 세트를 결합하는 연구 설계 도구입니다.
Illumina의 제품 및 서비스에 대한 정보 또는 Illumina의 기술 관련 질문에 대한 답변을 원하신다면 연락해 보세요.
귀하의 이메일 주소는 결코 제3자와 공유되지 않습니다.